虚拟网络优化与测试
从我们用户的使用就可以感受到网速一直在提升,而网络技术的发展也从1GE/10GE/25GE/40GE/100GE的演变,从中可以得出单机的网络IO能力必须跟上时代的发展。
现状与挑战
经过实践测试,在C8上跑应用每1W包处理需要消耗1%软中断CPU,这意味着单机的上限是100万PPS(Packet Per Second)。从TGW(Netfilter版)的性能100万PPS,AliLVS优化了也只到150万PPS,并且他们使用的服务器的配置还是比较好的。
假设,我们要跑满10GE网卡,每个包64字节,这就需要2000万PPS(注:以太网万兆网卡速度上限是1488万PPS,因为最小帧大小为84B《Bandwidth, Packets Per Second, and Other Network Performance Metrics》),100G是2亿PPS,即每个包的处理耗时不能超过50纳秒。而一次Cache Miss,不管是TLB、数据Cache、指令Cache发生Miss,回内存读取大约65纳秒,NUMA体系下跨Node通讯大约40纳秒。所以,即使不加上业务逻辑,即使纯收发包都如此艰难。我们要控制Cache的命中率,我们要了解计算机体系结构,不能发生跨Node通讯。
从这些数据,我希望可以直接感受一下这里的挑战有多大,理想和现实,我们需要从中平衡。问题都有这些:
- 传统的收发报文方式都必须采用硬中断来做通讯,每次硬中断大约消耗100微秒,这还不算因为终止上下文所带来的Cache Miss。
- 数据必须从内核态用户态之间切换拷贝带来大量CPU消耗,全局锁竞争。
- 收发包都有系统调用的开销。
- 内核工作在多核上,为可全局一致,即使采用Lock Free,也避免不了锁总线、内存屏障带来的性能损耗。
- 从网卡到业务进程,经过的路径太长,有些其实未必要的,例如netfilter框架,这些都带来一定的消耗,而且容易Cache Miss。
从前面的分析可以得知IO实现的方式、内核的瓶颈,以及数据流过内核存在不可控因素,这些都是在内核中实现,内核是导致瓶颈的原因所在,要解决问题需要绕过内核。所以主流解决方案都是旁路网卡IO,绕过内核直接在用户态收发包来解决内核的瓶颈。目前最热的解决方案就是DPDK了。
不过,我们先回到 openstack 环境中,看看可以优化的地方。首先是前面提到的DPDK,OVS已经为我们提供好了DPDK的版本;接着是开启网卡多队列,使得中断在多核CPU上进行负载均衡;还有一个是SR-IOV,这个可以直接逼近pass though的性能。现在有个问题,如果我们使用了SR-IOV,就直接抛弃了OVS,当然不需要使用OVS+DPDK的方案了,从理论上来说「去掉」要远远好于「优化」。所以最终在此次openstack环境中的网络优化采用了网卡对队列和SR-IOV的方式,如果还要继续优化,可以基于应用在虚机上使用DPDK,目前已经有了比较好的开源用户态网络协议栈:mtcp、f-stack。
重要性能参数科普
提到网络性能的参数,我们可能瞬间能想到延迟、带宽、吞吐量等等,但很可能不能清除的区分它们之间的关系代表的实际意义,接下来我们就大概谈一谈。
吞吐量 VS 带宽
吞吐量是在一个给定的时间段内介质能够传输的数据量。其与带宽是很容易搞混的一个词,两者的单位都是Mbps。先让我们来看两者对应的英语,吞 吐量:throughput,带宽: Max net bitrate 。当我们讨论通信链路的带宽时,一般是指链路上每秒所能传送的比特数。我们可以说以太网的带宽是10Mbps。但是,我们需要区分链路上的可用带宽(带宽)与实际链路中每秒所能传送的比特数(吞吐量)。我们倾向于用“吞吐量”一词来表示一个系统的测试性能。这样,因为实现受各种低效率因素的影响,所以由 一段带宽为10Mbps的链路连接的一对节点可能只达到2Mbps的吞吐量。这样就意味着,一个主机上的应用能够以2Mbps的速度向另外的一个主机发送数据。bps:bit per second
pps:packet per second包转发率
包转发率是用来衡量转发能力的,以能够处理最小包长来衡量,对于以太网最小帧为64BYTE(含14B帧头和4B帧尾),加上帧开销20BYTE(7B前导+1B定界符+12B帧间隔),因此最小包为84BYTE。
对于1个全双工1000Mbps接口达到线速时要求:转发能力=1000Mbps/((64+20)8bit)=1.488Mpps
对于1个全双工100Mbps接口达到线速时要求:转发能力=100Mbps/((64+20)8bit)=0.149Mpps线速转发
端口在满负载的情况下,对帧进行无差错的转发称为线速。
一般是指64字节的小包,能够做到网卡接口流量的转发不出现丢包.。比如千兆交换机,两个1000M口转发数据,一秒1400万(尾数就不写了,太老长)个64字节小包一个不丢。网络层的转发,应该是交换机起了三层路由功能后的转发性能。
每一种设备所重视的规格都不一樣- L2 Switch 重视的是交换能及背板大小
- L3 Switch 除了第一点外只要是进行Vlan Routing 及安全控管
- Router 重视的是效能和功能面
- Firewall 重视的是效能及连接数
延迟
时延是指一个报文或分组从一个网络的一端传送到另一个端所需要的时间。它包括了发送时延,传播时延,处理时延,排队时延。一般,发送时延与传播时延是我们主要考虑的。对于报文长度较大的情况,发送时延是主要矛盾;报文长度较小的情况,传播时延是主要矛盾。- 发送时延
发送时延是主机或路由器发送数据帧所需要的时间,也就是从发送数据的第一个比特算起,到该帧的最后一个比特发送完毕所需的时间。发送时延也称为传输时延。
发送时延 = 数据帧长度(b) / 信道带宽(b/s) - 传播时延
传播时延是电磁波在信道中传播一定的距离需要花费的时间。
传播时延 = 信道长度(m) / 电磁波在信道上的传播速率(m/s)
(电磁波在信道上的传播速率接近光速) - 处理时延
主机或路由器在收到分组时要花费一定的时间进行处理,就这产生了处理时延。 - 排队时延
分组在经过网络传输时,会经过许多路由器。分组在进入路由器之前要先在输入队列中排队等待处理。在路由器确定了转发接口后,还要在输出队列中排队等待转发。这就产生了排队时延。
- 发送时延
测试工具与方法
常见的网络性能测试工具有 iperf3 和 netperf,本次测试我们使用某位大神写的一个测试工具。
iperf3
安装
1 | yum install -y iperf3 |
运行
接收端:1
# iperf3 -s -i 1 -p 16000
发送端:1
# iperf3 -u -l 16 -b 100m -t 120 -c 192.168.10.10 -i 1 -p 16000 -A 1
主要参数
| 主要参数 | 参数说明 |
|---|---|
| -s | 表示作为server端接收包。 |
| -i | 间隔多久输出信息流量信息,默认单位为秒。 |
| -p | 指定服务的监听端口。 |
| -u | 表示采用UDP协议发送报文,不带该参数表示采用TCP协议。 |
| -l | 表示包大小,默认单位为Byte。通常测试PPS的时候该值为46,测试bps时该值为1500。 |
| -b | 设定流量带宽,可选单位包括:k/m/g。 |
| -t | 流量的持续时间,默认单位为秒。 |
| -A | CPU亲和性,可以将具体的iperf3进程绑定对应编号的逻辑 CPU,避免iperf进程在不同的CPU间调度。 |
输出说明
最终发送端每个 iperf3 进程会输出如下结果,第一条数据行为发包信息概览如下:1
2
3[ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[4] 0.00-10.00 sec 237 MBytes 199 Mbits/sec 0.027 ms 500/30352 (1.6%)
[4] Sent 30352 datagrams
输出结果中各字段含义解释如下表所示:
| 字段 | 含义 |
| ——— | —– |
| Transfer | 传送的总数据量 |
| Bandwidth | 带宽大小 |
| Jitter | 波动率 |
| Lost/Total | 丢包/总报文数 |
| Datagrams | 丢包率 |
PPS = 对端收到的包/时间
通常我们建议在 server 端运行 sar 来统计实际收到的包并作为实际结果,具体命令为: sar -n DEV 1 320。
netperf
安装
1 | wget -c "https://codeload.github.com/HewlettPackard/netperf/tar.gz/netperf-2.5.0" -O netperf-2.5.0.tar.gz |
运行
接收端:1
# netserver -p 16000
发送端:1
# netperf -H 172.0.0.1 -p 11256 -t UDP_STREAM -l 300 -- -m 1500
主要参数
接收端:
| 主要参数 | 参数说明 |
| ——— | ———– |
| -p | 端口号 |
发送端:
| 主要参数 | 参数说明 |
| ——— | ———– |
| -H | 指定 ECS 实例的 IP 地址。|
| -p | 指定 ECS 实例的端口。|
| -l | 指定运行时间。|
|-t | 指定发包协议类型:TCP_STREAM 或 UDP_STREAM。建议使用 UDP_STREAM。|
| -m | 指定数据包大小:测试 PPS 时,该值为 46;测试bps(bit per second)时,该值为1500。|
输出说明
最终发送端每个 netperf 进程会输出如下结果,第一条数据行为发包信息概览如下:1
2
3
4
5
6Socket Message Elapsed Messages
Size Size Time Okay Errors Throughput
bytes bytes secs # # 10^6bits/sec
124928 1 10.00 4532554 0 3.63
212992 10.00 1099999 0.88
输出结果中各字段含义解释如下表所示:
| 字段 | 含义 |
| ——— | —– |
| Socket Size bytes | 缓冲区大小 |
| Message Size bytes | 数据包大小(Byte) |
| Elapsed Size bytes | 测试时间(s)|
| Okey | 数据包成功数 |
| Errors | 失败数 |
| Throughput | 网络吞吐量(Mbit/s)|
PPS = 数据包成功数/测试时间
通常我们建议在 server 端运行 sar 来统计实际收到的包并作为实际结果,具体命令为: sar -n DEV 1 320。
本次测试工具
安装
1 | yum install -y git gcc clang |
运行
接收端:
(四进程并置位SO_REUSEPORT)1
taskset -c 1,2,3,4 ./udpreceiver1 0.0.0.0:4321 4 1
发送端:
(两进程)1
taskset -c 1,2 ./dump/how-to-receive-a-million-packets/udpsender 192.168.111.120:4321 192.168.111.120:4321
测试方法
- 本次测试方便起见没有搭建openstack集成好的环境,而是直接使用KVM和SR-IOV进行测试。
- 避免受限于软件程序的发包能力,测试采用“多VM发,1 VM收”的方式来测试接收端网络性能,当接收端数据不再增长甚至开始下降时认为达到峰值。接收端x1:4c8g 60G 4线程;发送端xN:2c2g 20G 2线程。
- 为了避免单机OVS等的影响因素,发送端位于不同节点。
开启网卡多队列
方式一:直接修改xml文件
(区别于virtio技术,SR-IOV暂没找到直接开启的方式,建议使用方式二)
判断宿主机是否支持网卡多队列可以参见(虚机方面,virtio已经支持。):https://www.jianshu.com/p/1dfe40305bb5,里面网卡多队列原理和CPU中断亲和性等设置方法讲的也很详细。
查看网卡多对列
1
2
3
4
5
6
7
8
9
10
11
12# ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 1
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 1找到对应的宿主机,使用virsh命令编辑虚拟机的xml文件来添加网卡多队列。
这里需要注意的是,所使用的驱动应该与系统所能支持的虚拟网卡驱动相同。在openstack中常见的有vhost和vhost-user两种类型的驱动。这里我们没有启用dpdk,所以需要开启vhost类型驱动。
参数queues表示该网卡所开启的队列数,按照需求开启队列数。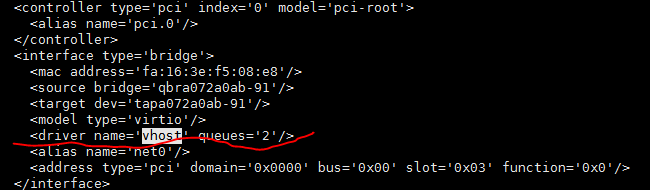
在使用virsh命令编辑完xml文件之后重启虚机,然后进入虚机查看该网卡队列数和对应的内核中断数。
1
2
3
4
5
6
7
8
9
10
11# ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0 Other: 0
Combined: 4 # 这一行表示最多支持设置4个队列
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 4 #表示当前生效的是4个队列如果当前生效的仍未是4个队列可以考虑用一下命令设置网卡队列为4。
1
# ethtool -L eth0 combined 4 # 设置eth0当前使用4个队列
使用命令查看是否产生了对应4个队列的中断。
1
# cat /proc/interrupts
方式二:通过OpenStack的metadata
更新镜像:1
# glance image-update --property hw_vif_multiqueue_enabled=true ${IMAGE_ID}
开启SR-IOV(非openstack集成)
Redhat官方文档:Using SR-IOV
准备物理网卡
在环境中有一块Intel 82599万兆物理网卡,对应环境中的eth6, eth7。1
20000:06:00.0 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
0000:06:00.1 Ethernet controller: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection (rev 01)
对网卡开启SRIOV的支持,网卡最多支持63个VF1
2
3
4
5
6
7
8# echo 4 > /sys/class/net/eth6/device/sriov_numvfs
# ip link show
9: eth6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT qlen 1000
link/ether 90:e2:ba:94:2e:b4 brd ff:ff:ff:ff:ff:ff
vf 0 MAC ba:af:d6:1a:4f:df, spoof checking on, link-state auto, trust off
vf 1 MAC 52:54:00:31:cf:5c, spoof checking on, link-state auto, trust off
vf 2 MAC 56:fc:bb:dc:16:bd, spoof checking on, link-state auto, trust off
vf 3 MAC 22:53:0b:ac:29:89, spoof checking on, link-state auto, trust off
开启物理机passthrough功能
有两处地方需要修改:
- BIOS中开启INTEL VT-D的扩展
- 在系统引导中添加intel_iommu=on到grub的配置中
重启系统
获取VF PCI地址
1 | # 首先获取网卡的pci地址,该网卡的pci地址为06:00.0 |
准备xml
上面我们已经获得到了VF device 的domain, host, function,根据这些的信息,准备xml文件,注意vlan的ID。1
2
3
4
5
6
7
8<interface type='hostdev' managed='yes'>
<source>
<address type='pci' domain='0x0' bus='0x06' slot='0x10' function='0x2'/>
</source>
<vlan>
<tag id='2010'/>
</vlan>
</interface>
准备虚拟机
创建一台4c8g的虚拟机用来作为passthrough的主机, 并attach VF设备
virsh attach-device 21 cc.xml –live –config
–live 直接加载进正在运行的虚机
–config 把xml文件内容写进虚机xml文件,避免重启配置丢失,当然调用nova的话配置仍然会被重置
登陆到虚拟机内,VF设备已经attach到虚拟机上,该虚拟机的eth0为neutron创建的device,eth1则是透传进去的VF。1
2
3
4
5ip link set dev eth1 up
ip addr del 192.168.111.120/24 dev eth0
ip addr add 192.168.111.120/24 dev eth1
# 添加默认路由
route add default gw 192.168.111.1
优化结果
| Initial | SR-IOV | |
|---|---|---|
| Single queue | 45w | 65w |
| Multi queue | 80w | 120w |
*注:数据为包转发率,pps。
另外推荐一篇网络压测博文:KVM网络性能压测